 Comunicações em radio sempre me trouxeram muita curiosidade, Q o que? Charlie, Tango, Roger that e outros. Então decidi “traduzir” algumas coisas aqui neste post. Vamos começar pelo alfabeto fonético nacional, usado por algumas instituições militares estaduais e grupos turísticos.
Comunicações em radio sempre me trouxeram muita curiosidade, Q o que? Charlie, Tango, Roger that e outros. Então decidi “traduzir” algumas coisas aqui neste post. Vamos começar pelo alfabeto fonético nacional, usado por algumas instituições militares estaduais e grupos turísticos.
A = AFIR
B = BALA
C = CRUZ
D = DEDO
E = ELMO
F = FACE
G = GATO
H = HORA
I = INTE
J = JOIA
K = KILO
L = LUAR
M = MARÉ
N = NEGA
O = ONDA
P = PREP
Q = QUER
R = RATO
S = SOLO
T = TUPI
U = URSO
V = VIGA
W = VEVE
X = XARA
Y = YOLE
Z = ZAGA
Agora o fonético internacional e mais conhecido e utilizado pelo mundo todo, incluindo a Policia Federal.
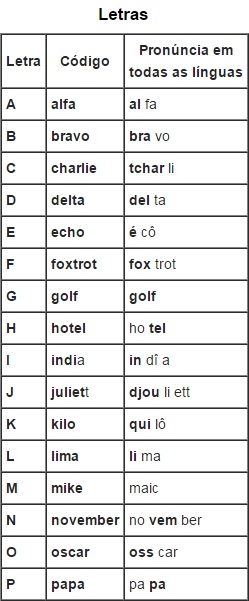
A = ALFA,
B = BRAVO,
C = CHARLIE,
D = DELTA,
E = ECO,
F = FOX,
G = GOLF,
H = HOTEL,
I = INDIA,
J = JULIETT,
K = KILO,
M = MIKE,
N = NOVEMBER,
O = OSCAR,
P = PAPA,
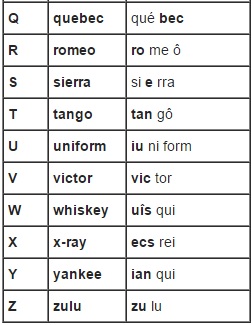
Q = QUEBEC,
R = ROMEO,
S = SIERRA,
T = TANGO,
U = UNIFORM,
V = VICTOR,
W = WHISKY,
X = XREY,
Y = YANKEE,
Z = ZULU
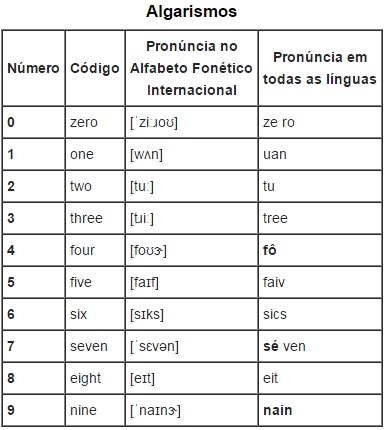
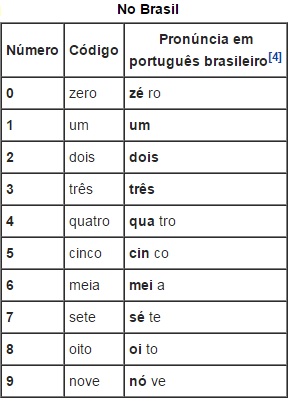
Os numeres em inglês são: Uno = 1, Duo = 2, os outros são de pronuncia normal. No Brasil se diz: primeiro, segundo, terceiro, quarto, quinto, sexto, sétimo, oitavo, nono e negativo para representar o Zero. Tais codificações são utilizadas para não confundir as letras, como por exemplo D, B, P que devido a qualidade da comunicação em radio ser baixa pode ocorrer erros na transmissão e recepção.
Para a curiosidade, traduzam a frase
ELMO SOLO TUPI ELMO JÓIA AFIR MARE PREP RATA ELMO PREP AFIR RATA AFIR DEDO ONDA SOLO
Ou no alfabeto internacional (que eu acho mais legal)
ECO SIERRA TANGO ECO JULIETT ALFA MIKE PAPA ROMEO ECO PAPA ALFA ROMEO ALFA DELTA OSCAR SIERRA
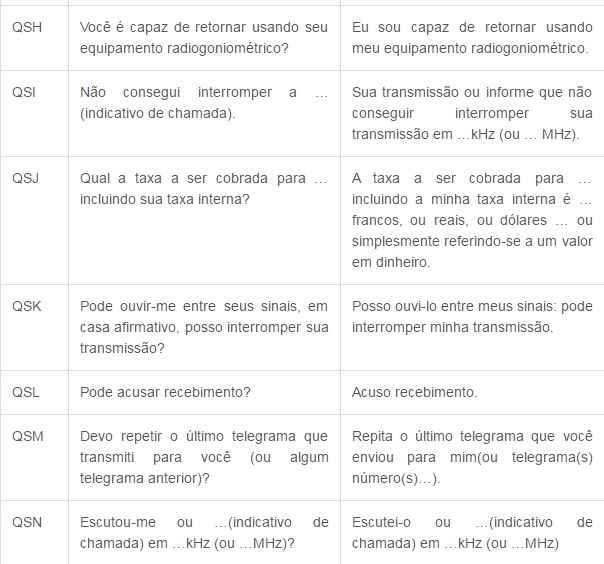
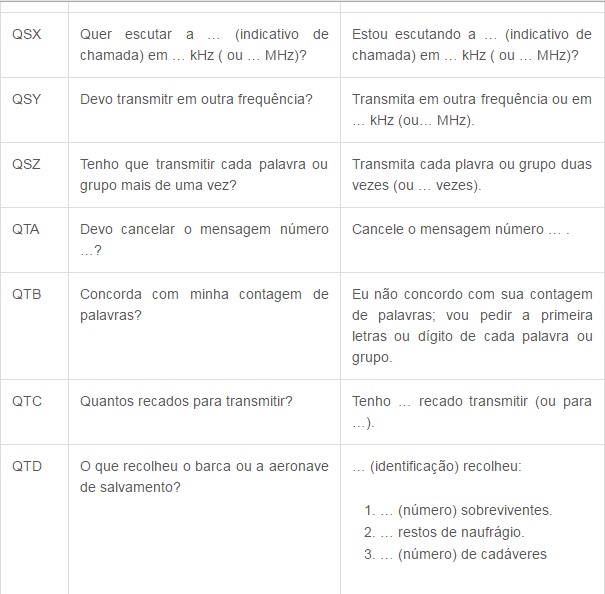
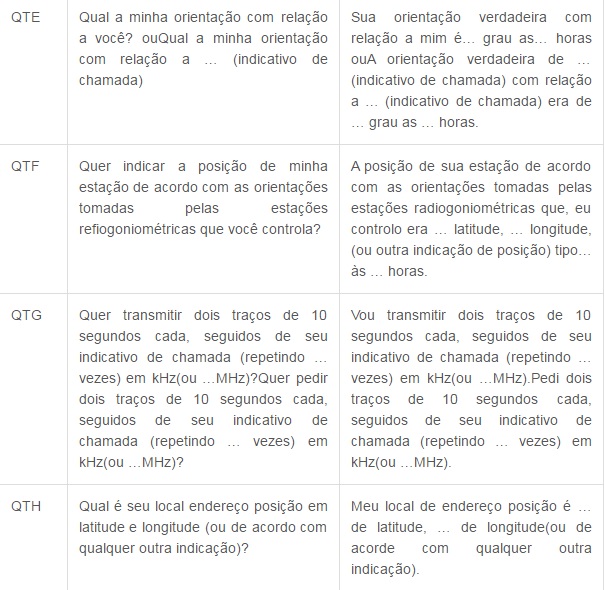
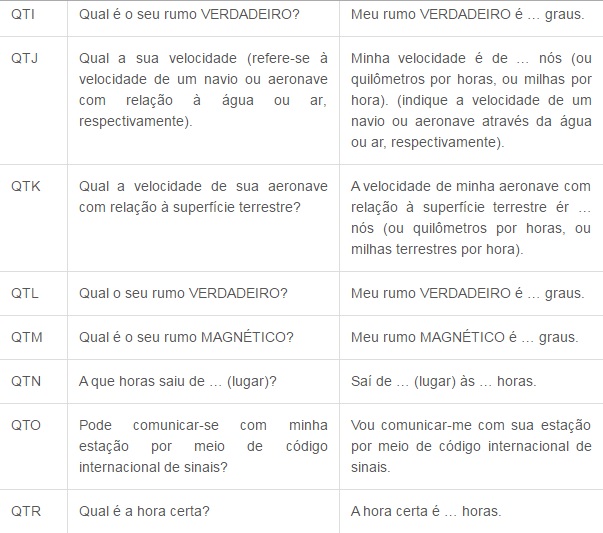
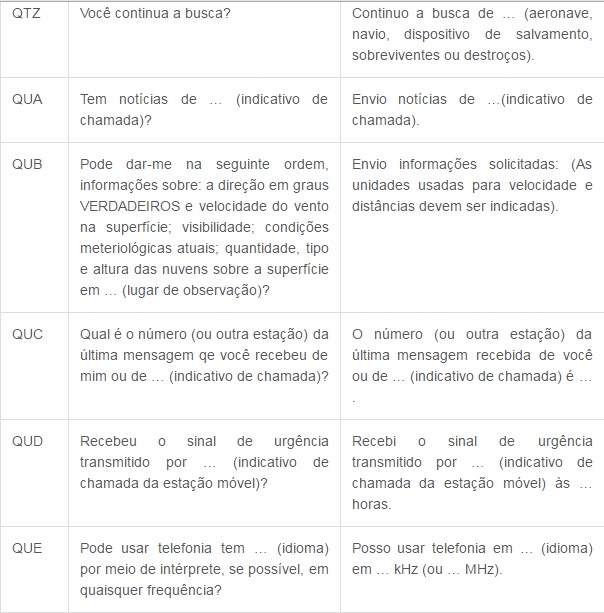
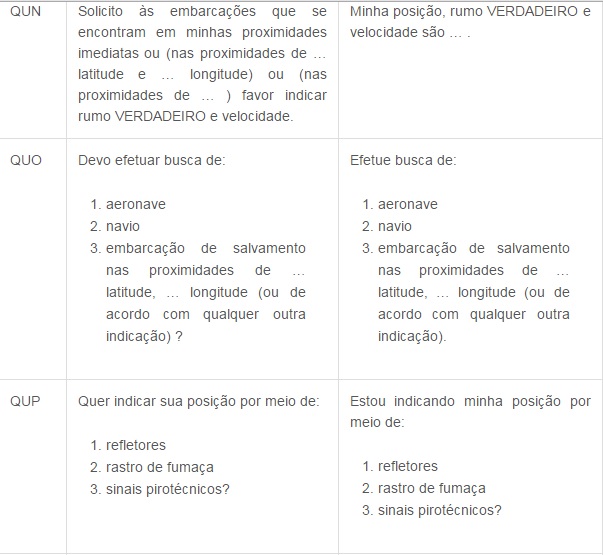
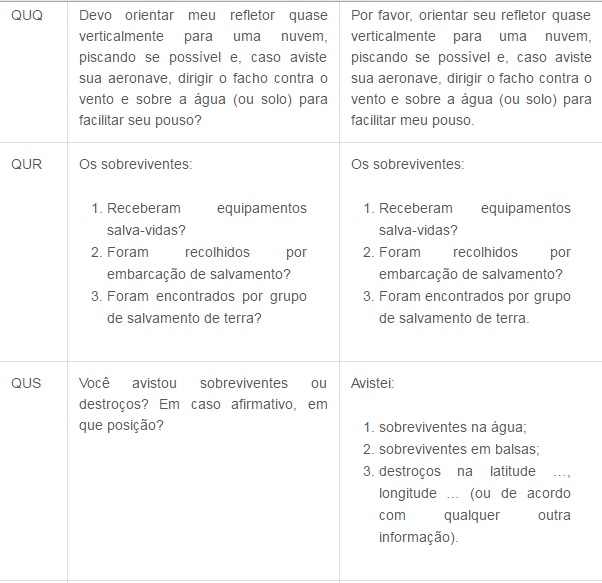
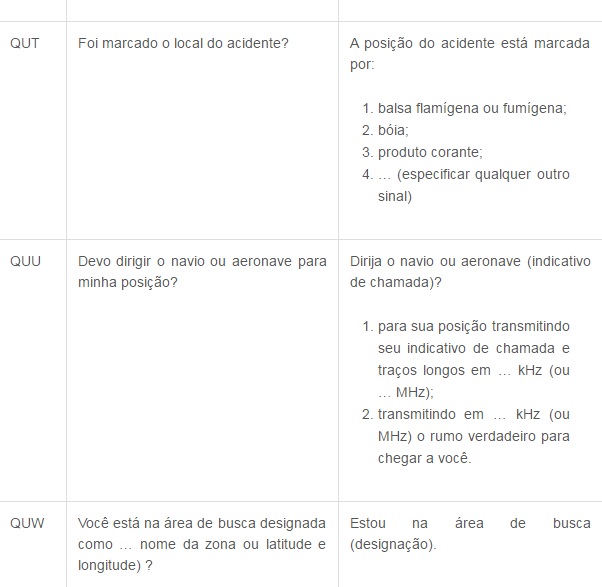
Agora segue a tabela do Código Q, que é internacionalmente utilizado para comunicação em rádios. Decide postar os mais utilizados, devido a uma gama enorme de códigos, cada um contendo uma mensagem diferente.
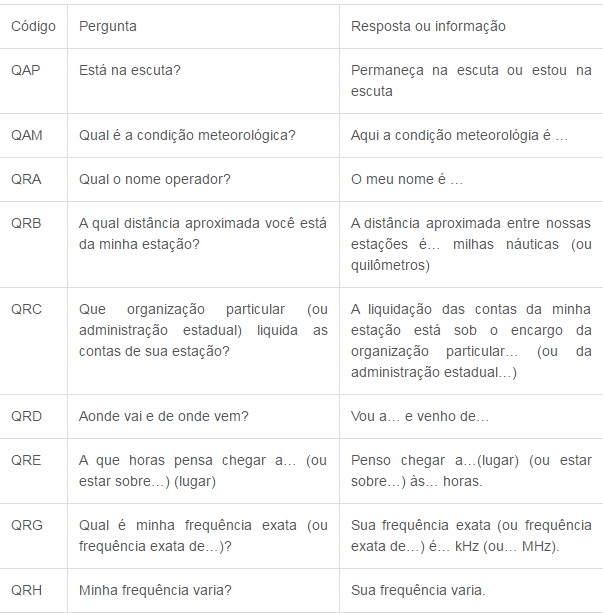

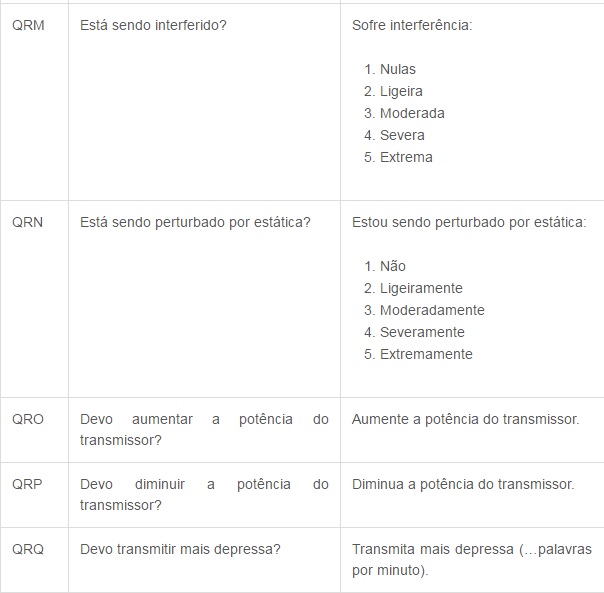
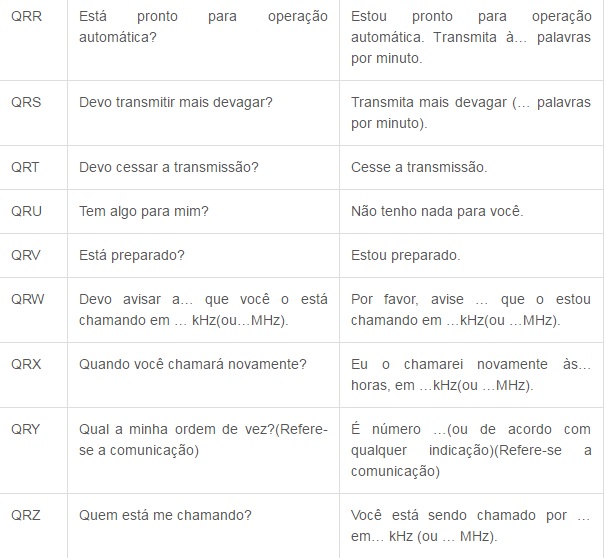
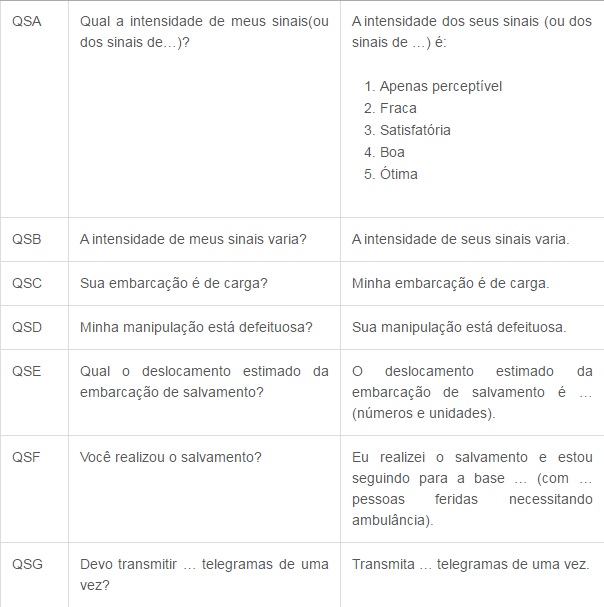




Alfabeto fonético da OTAN
Não confundir com Alfabeto fonético internacional. O alfabeto fonético da OTAN é o alfabeto de soletração mais utilizado no mundo. Embora chamados de "alfabetos fonéticos", alfabetos de soletração não têm conexão com sistemas de transcrição fonética como o alfabeto fonético internacional. Ao invés disso, o alfabeto da OTAN define palavras-chave para letras do alfabeto inglês por meio de um princípio acrofônico (Alfa para A, Bravo para B, etc.) para que combinações críticas de letras (e números) possam ser pronunciadas e entendidas por aqueles que transmitem e recebem mensagens de voz por rádio ou telefone, independente de seu idioma nativo, especialmente quando a segurança de navegação ou de indivíduos é essencial. É informalmente conhecido como "alfabeto Zulu" na aeronáutica brasileira.
Depois que o alfabeto foi desenvolvido pela Organização da Aviação Civil Internacional, foi adotado por várias organizações internacionais como a Organização do Tratado do Atlântico Norte (OTAN), a União Internacional de Telecomunicações (UIT), a Organização Marítima Internacional (OMI), a Federal Aviation Administration (FAA) e o American National Standards Institute (ANSI). Deriva-se do muito mais antigo Código internacional de sinais, que originalmente abrangia sinais visuais luminosos ou por bandeiras, sinais sonoros por apitos, sirenes, buzinas e sinos, assim como um, dois ou três códigos de letras para várias frases.
O mesmo código alfabético é utilizado por todas as agências, mas cada uma escolhe uma ou duas seleções diferentes de códigos numéricos. A OTAN utiliza as palavras numéricas padrão em inglês (Zero, One, com pronúncias alternativas), enquanto a OMI utiliza palavras compostas (Nadazero, Unaone, Bissotwo, etc.). Na prática esses últimos são raramente usados, pois podem provocar confusão entre interlocutores de diferentes nacionalidades.
O nome comum do alfabeto (alfabeto fonético da OTAN) surgiu pois ele aparece na publicação Allied Tactical Publication ATP-1, Volume II: Allied Maritime Signal and Maneuvering Book, usado por todas as esquadras aliadas da OTAN, que adotaram uma forma modificada do Código Internacional de Sinais. Por este último permitir que mensagens fossem transmitidas por bandeiras ou código Morse, naturalmente denominou as palavras-chave usadas para transmitir mensagens faladas de "alfabeto fonético".
Desde que os sinais usados para facilitar as comunicações e táticas navais dos Estados Unidos e da OTAN se tornaram globais, o nome "alfabeto fonético da OTAN" tornou-se um consenso. No entanto, a publicação ATP-1 é classificada como confidencial, e consequentemente não está disponível para consulta pública. Há uma versão do documento disponibilizada a marinhas estrangeiras e até mesmo hostis, que, contudo, também não pode ser divulgada. No entanto, atualmente o alfabeto fonético já aparece em outros documentos militares internacionais não secretos.
Alfabeto fonético internacional
O alfabeto fonético internacional (referenciado pela sigla AF e pela sigla em inglês IPA, de International Phonetic Alphabet) é um sistema de notação fonética baseado no alfabeto latino, criado pela Associação Fonética Internacional como uma forma de representação padronizada dos sons do idioma falado. O AFI é utilizado por linguistas, fonoaudiólogos, professores e estudantes de idiomas estrangeiros, cantores, atores, lexicógrafos e tradutores.
O AFI foi projetado para representar apenas aquelas características da fala que podem ser distinguidas no idioma falado: fonemas, entonação, e a separação de palavras e sílabas. Para representar características adicionais da fala, como o ranger dos dentes, sigmatismo (língua presa) e sons feitos com lábios leporinos, utiliza-se de um conjunto ampliado de símbolos, chamados de extensões ao AFI.
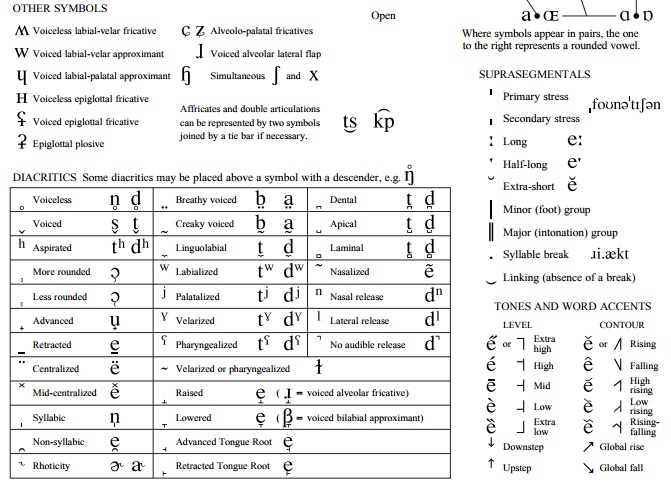
Ocasionalmente letras ou diacríticos são adicionados, removidos, ou modificados pela Associação Fonética Internacional. A partir da alteração mais recente em 2015, existem 107 letras, 52 diacríticos, e quatro marcas de prosódia no AFI. Os símbolos do alfabeto fonético internacional são divididos em três categorias: letras (que indicam os sons básicos), diacríticos (que especificam mais esses sons básicos) e supra-segmentais (que indicam características, como velocidade, tom e acento tônico). Essas categorias são divididas em seções menores: as letras podem ser vogais ou consoantes e os diacríticos e supra-segmentais são classificados de acordo com o que indicam: articulação, fonação, tom, entonação ou acentuação tônica.
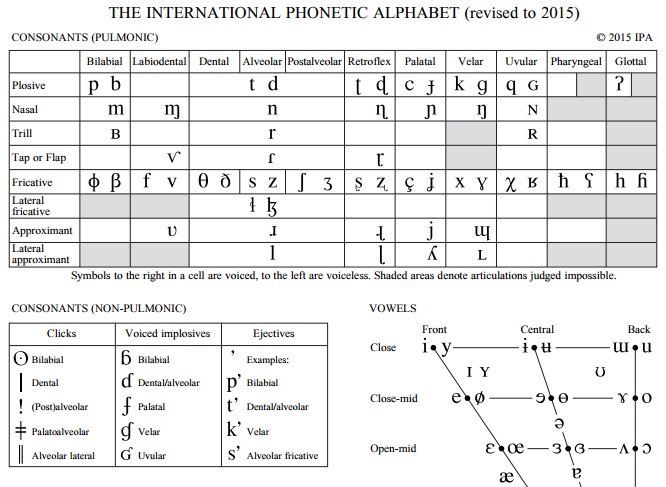
O princípio geral do alfabeto fonético internacional é fornecer um símbolo para cada som ou segmento de fala distinto. Isto significa que o alfabeto não se utiliza de combinações de letras para representar sons únicos, ou de letras únicas para representar mais de um som (como o <x> pode representar no português). Não existem letras que têm valores sonoros diferentes de acordo com o contexto (como o <c> possui no português e em outros idiomas europeus) e, finalmente, o AFI não costuma ter letras separadas para dois sons, se nenhuma língua conhecida fizer distinção entre eles (uma propriedade conhecida como "seletividade").
Entre os símbolos do alfabeto, 107 representam consoantes e vogais, 31 são diacríticos utilizados para especificar ainda mais estes sons, e 19 são utilizados para indicar características como quantidade, tom, tonicidade e entonação.
Existem duas maneiras de utilizar os caracteres do alfabeto fonético internacional para transcrever um determinado idioma: pode-se representar os fonemas, através da a transcrição fonológica (que transcreve os caracteres entre barras) e a transcrição fonética, que representa os sons dos fonemas (e costuma transcrever os caracteres entre colchetes).
Embora o AFI ofereça mais de cem símbolos para transcrever a fala, não é necessário que se utilize de todos os símbolos relevantes ao mesmo tempo; é possível transcrever a fala com diferentes níveis de precisão. O tipo mais preciso de transcrição fonética, no qual os sons são descritos com o maior nível de detalhe que o sistema permite, sem qualquer preocupação com a significância linguística das distinções feitas desta maneira, é conhecido como transcrição estreita, ou detalhada. Qualquer outra coisa recebe o nome de transcrição larga ou ampla, embora estes termos sejam, obviamente, relativos. Os dois tipos de transcrição são representadas geralmente entre colchetes, porém a transcrição larga por vezes pode estar entre barras e não colchetes.
A transcrição larga apenas distingue entre os sons que são considerados diferentes pelos falantes de um determinado idioma. Os sons que são pronunciados diferentemente de acordo com os dialetos ou estilos do idioma, ou de acordo com os sons vizinhos, podem ser considerados como sendo sons "iguais" já que são alófonos dos mesmos fonemas. Por exemplo, a pronúncia da palavra "porta" pode ser transcrita de maneira ampla utilizando-se do AFI como /p??t?/, e esta transcrição larga (e imprecisa) é uma descrição correta de muitas, ainda que não todas, as pronúncias da palavra no português. Esta transcrição ampla meramente identifica os diferentes componentes foneticamente relevantes da palavra, sem indicar a variedade de sons correspondentes. Por outro lado, as transcrições estreitas (colocadas entre colchetes) especificam a maneira com que cada som é pronunciado. Uma transcrição mais estreita de "porta" iria variar de acordo com a maneira, o sotaque ou o dialeto em que for falada: [p??ht?], [p???t?] e [p???t??] são algumas das possibilidades.
Nem a transcrição larga nem a estreita para o alfabeto fonético internacional fornecem uma descrição absoluta; elas são descrições relativas dos sons fonéticos. Esta definição se aplica especialmente às vogais no AFI: não existe um mapeamento rápido e consistente entre os símbolos do alfabeto e as faixas de frequência formantes, dependendo da fonologia do idioma em questão.
Fonte: https://sobrevivencialismo.com
https://pt.wikipedia.org/